publications
publications by categories in reversed chronological order.
2025
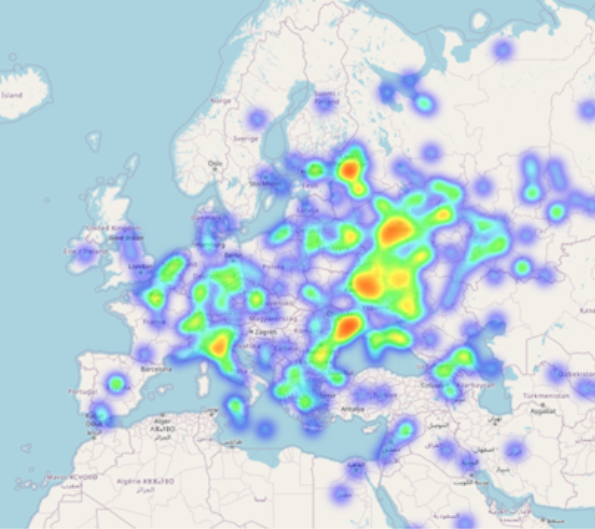
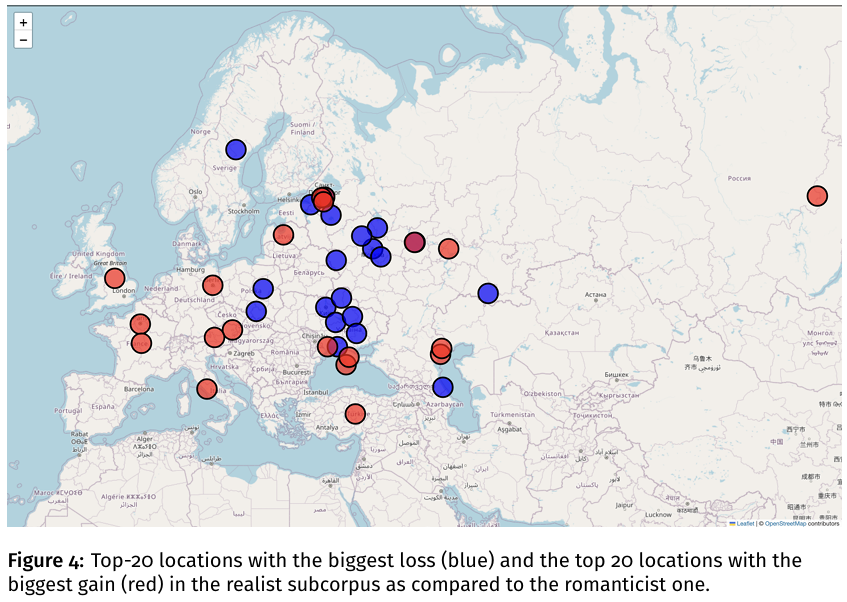
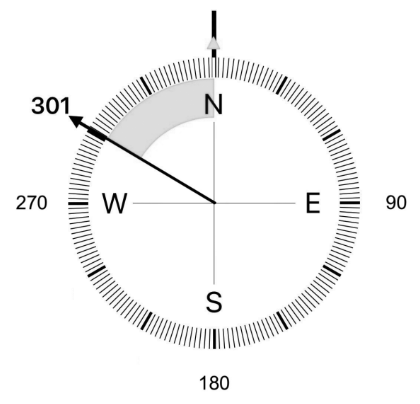
2024
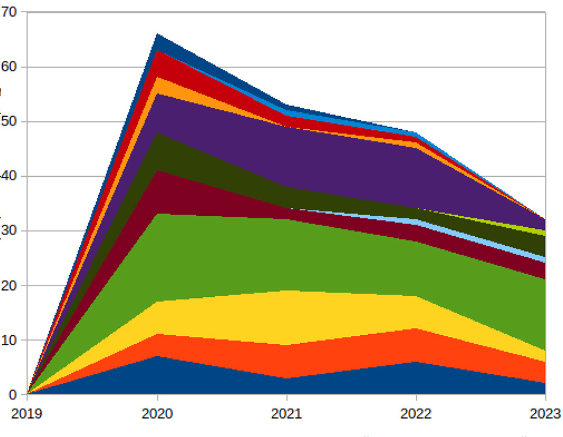
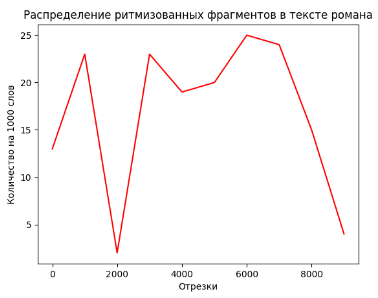

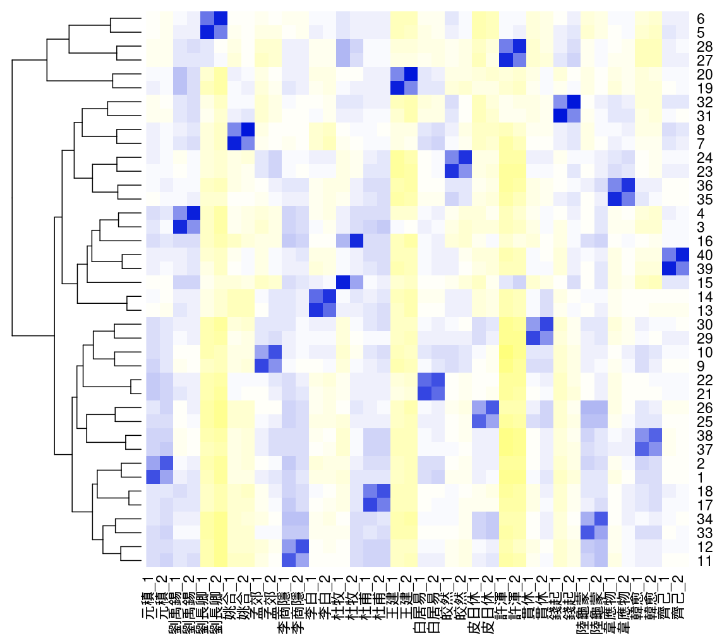

2023
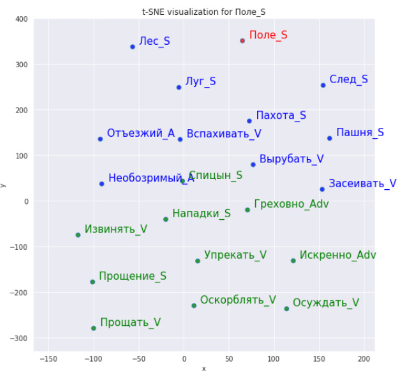
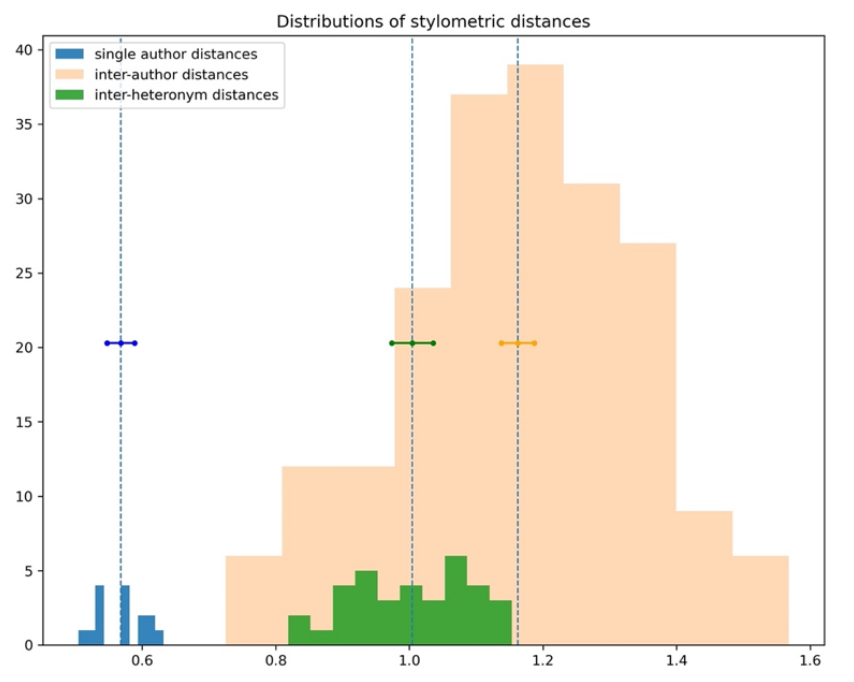

2022
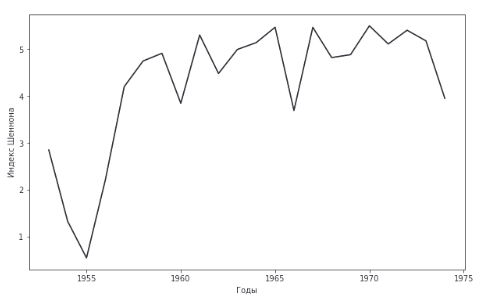
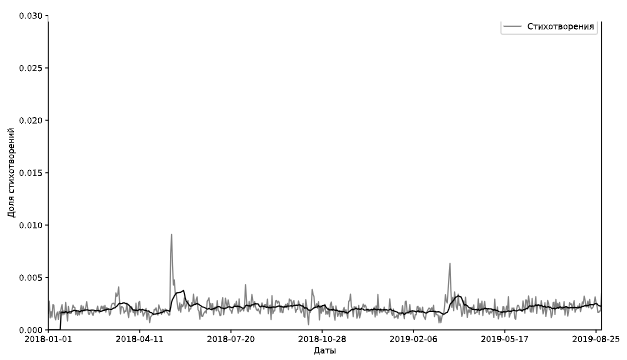
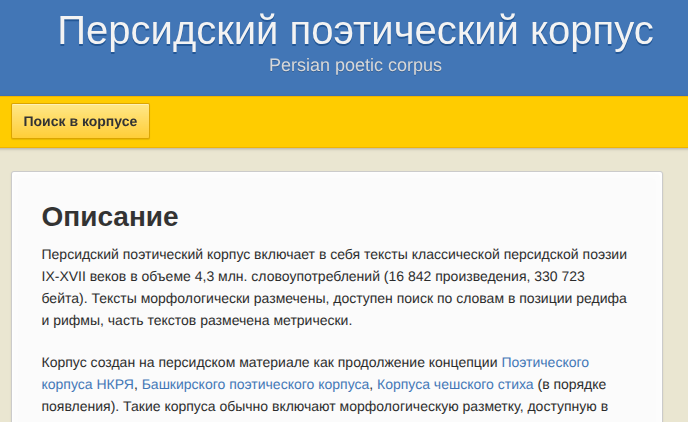
2021
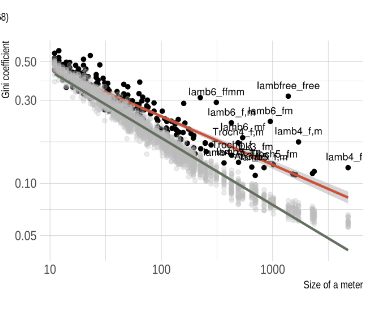
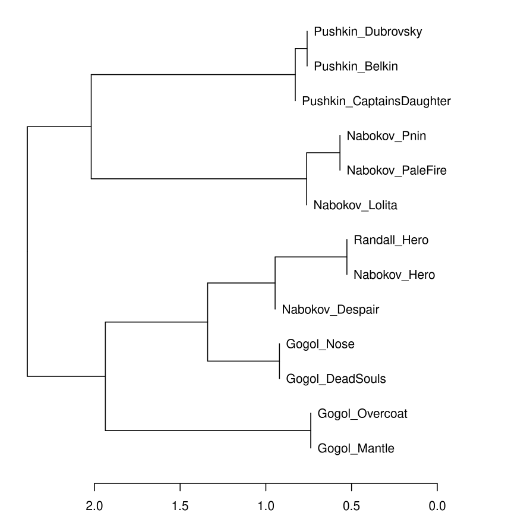
2020


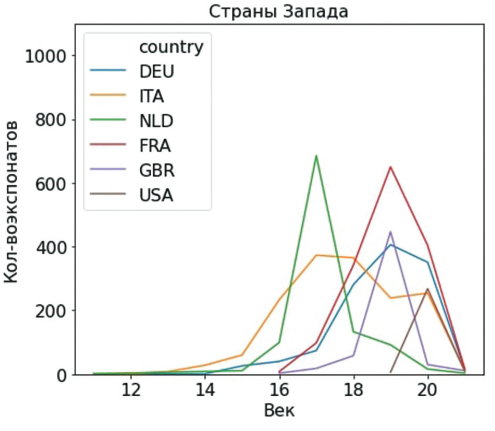

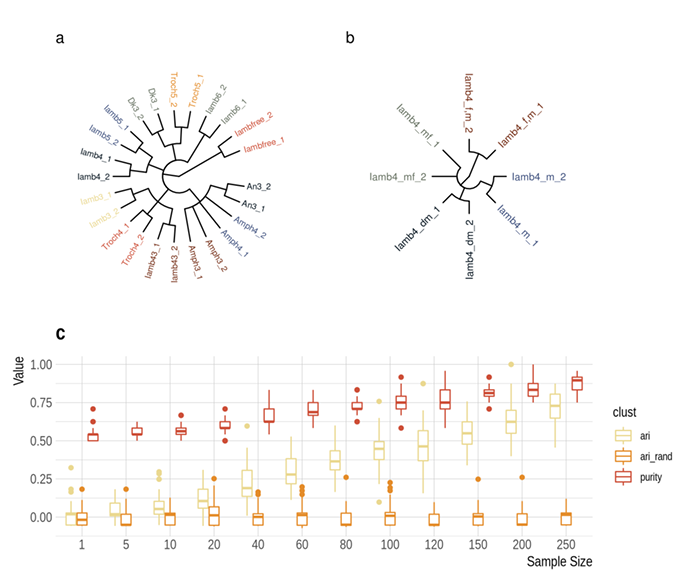
2019

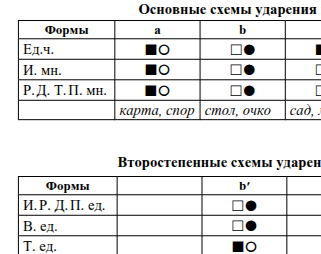
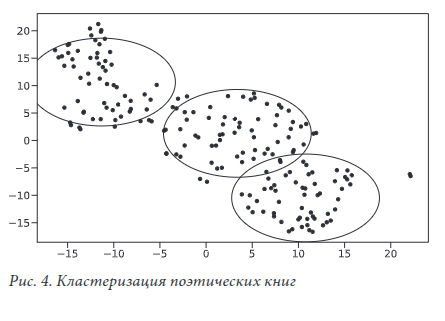
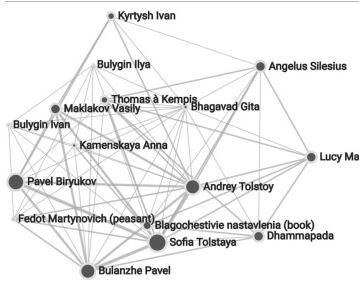
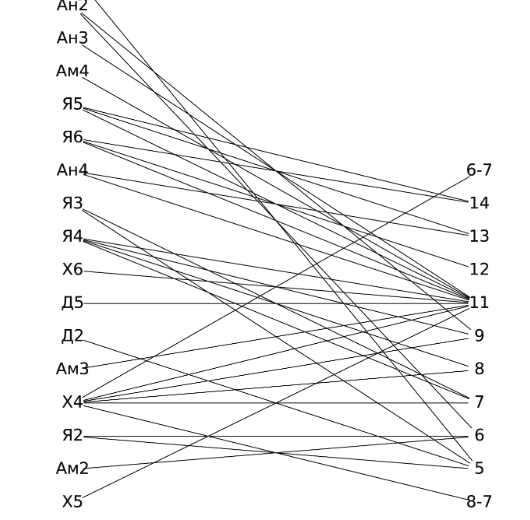
2018
- Тезисы докладовThe 91st Volume-How the Digitised Index for the Collected Works of Leo Tolstoy Adds A New Angle for ResearchIn Digital Humanities 2018. Puentes-Bridges. Book of Abstracts, Mar 2018
- Тезисы докладовThe History and Context of the Digital Humanities in RussiaIn Digital Humanities 2018. Puentes-Bridges. Book of Abstracts, Mar 2018

2017
- БашкирскийCris d’animaux en langue bachkire: infuence russe et métaphorisationIn Verba sonandi : les représentations linguistiques des cris d’animaux, Mar 2017
- СПИLe bestiaire médiéval dans un contexte surréaliste : à propos d’une traduction de Slovo o polku Igoreve par Philippe SoupaultIn Verba sonandi : les représentations linguistiques des cris d’animaux, Mar 2017
- Тезисы докладовMake index great again: электронный указатель к 90-томнику Л. Н. ТолстогоIn Информационные технологии в гуманитарных науках. Тезисы докладов конференции, Mar 2017
2016
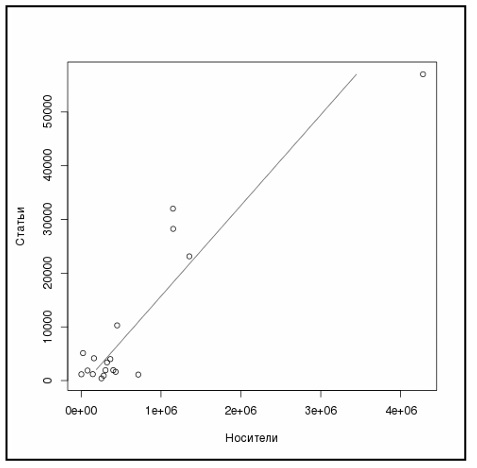
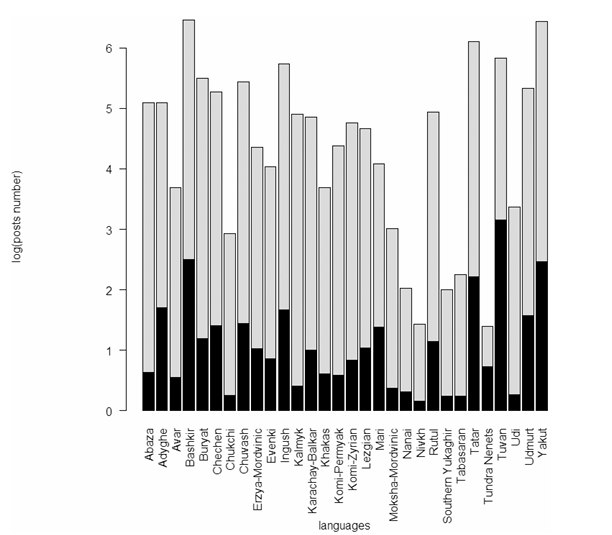
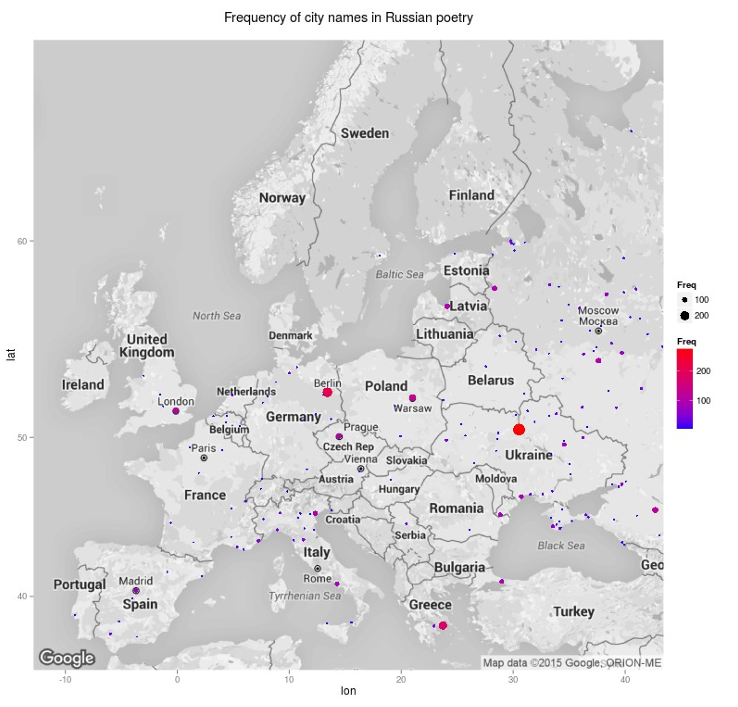
2015
- История литературы как автопортретIn Третье литературоведение : ученые записки филолого-методологического семинара (2008–2009), Mar 2015
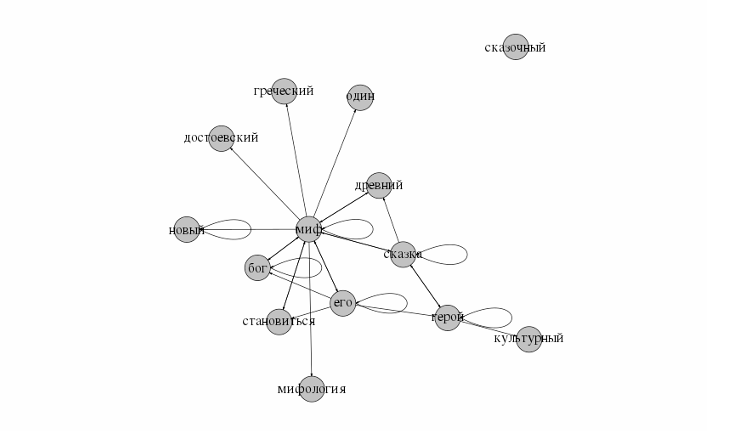
2014
- КорпусБашкирский поэтический корпусIn Корпусный анализ русского стиха: Сборник научных статей. Вып. 2, Mar 2014
-
- ИнтернетБашкирский сегмент Интернета: семиотика и лингвистикаIn Русский язык и новые технологии / Коллективная монография, Mar 2014
-
- Тезисы докладовDistant reading of naïve poetry: corpora comparison as research methodologyIn Digital Humanities 2014. Conference Abstracts, Mar 2014
- Тезисы докладовМежслоговой сингармонизм в структуре башкирского стихаIn Методология и практика русского формализма: Бриковский сборник, Mar 2014
- Тезисы докладовПеревод «Слова о полку Игореве» Н. И. Язвицкого: генетические связи и особенности рецепцииIn IV Международный симпозиум «Русская словесность в мировом культурном контексте». Избранные доклады и тезисы, Mar 2014
2013
- ХроникаМеждународная конференция «Неудобное знание: социальная симптоматика и эпистемологическая рефлексия» (РАНХиГС, Москва / Обнинск, 25–27 октября 2012 г.)Новое литературное обозрение, Mar 2013
-
- Тезисы докладовИдиоглосса «записка» в словаре «Записок ружейного охотника Оренбургской губернии»In Аксаковские чтения : (материалы ХIV Международных Аксаковских чтений. Уфа, 26–27 сентября 2013 г.), Mar 2013
- Тезисы докладовМетрический репертуар советской башкирской поэзииIn Сохранение и развитие родных языков и литератур в условиях многонационального государства: проблемы и перспективы. Материалы международной научно-практической конференции, посвященной 85-летию доктора филологических наук, профессора, академика АН РБ, заслуженного деятеля науки РБ и РФ, народного писателя РБ, лауреата Государственной премии имени С. Юлаева, почетного профессора БашГУ Гайсы Батыргареевича Хусаинова, Mar 2013
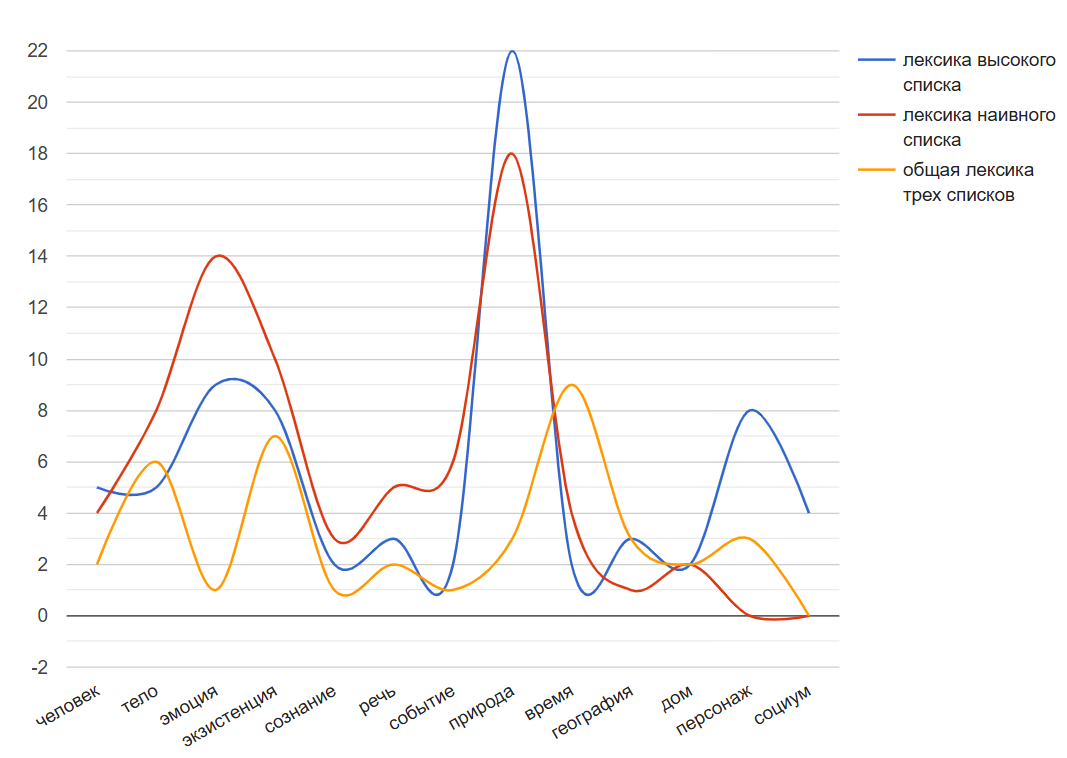
2012
-
- НазировПредисловие к публикации статьи Р. Г. Назирова «Герои раннего Гоголя»In Литературная классика: публикации, комментарии, отражения. Сборник научных трудов, Mar 2012
- «От русского по прочтении отрывков из лекций г-на Мицкевича» Ф. И. Тютчева: комментатору на заметкуIn Литературная классика: публикации, комментарии, отражения. Сборник научных трудов, Mar 2012
- «Кровавый закат звезды римской славы»: о возможной связи текстов Ф. И. Тютчева и ЦицеронаIn Литературная классика: публикации, комментарии, отражения. Сборник научных трудов, Mar 2012
- КорпусThe Polish-Russian Parallel Corpus and Its Application in the Linguistic AnalysisPrace Filologiczne, Mar 2012
- Воскресение жанра: сетевая эротическая литератураIn Культ-товары-XXI: ревизия ценностей (Масcкультура и её потребители: Коллективная монография, Mar 2012
-
- Назиров
- СПИЖивотный мир «Слова о полку Игореве» в переводе Филиппа Супо «Le Chant du Prince Igor»In Бестиарий в словесности и изобразительном искусстве: cб. статей., Mar 2012
- Тезисы докладовПоэтическое в языке и двуязычные словари: о возможностях количественных методовIn Восток — Запад: проблемы межкультурной коммуникации: сб. науч. ст. межрегион. научн.-практ. конф. с междунар. участием, Петропавловск-Камч., 16–17 ноября 2012 г., Mar 2012
- Тезисы докладовСнова об алгебре и гармонии: количественные критерии для лексических поэтизмовIn Когнитивные и коммуникативные аспекты дискурсивной деятельности:Материалы Международной научно-практической конференции 11-12 декабря 2012., Том 2., г. Уфа, Mar 2012
2011
- Сюрреалистическая рецепция фольклорных мотивов в стихотворении А. Бретона «Le puits enchante»In Историческая поэтика жанра: Сб. научных трудов., Mar 2011
- ПереводСтереоскопичность идентификации поэтического переводного текста в сознании индивидаВестник ВЭГУ, Mar 2011
- Назиров
- Хроника
-
- Тезисы докладовО формализованном описании башкирского стихаIn Профессор Джалиль Гиниятович Киекбаев и его вклад в развитие урало-алтайской и тюркской филологии. Материалы Международной научно-практической конференции, посвященной 100-летию со дня рождения известного башкирского ученого-тюрколога, писателя и общественного деятеля Дж. Г. Киекбаева, Mar 2011
- Тезисы докладовНаучный архив профессора Р. Г. НазироваIn Русское слов в Республике Башкортостан: Материалы региональной научно-теоретической конференции, Mar 2011
- Тезисы докладовФольклорно-мифологический план в повести в стихах «Мистер Твистер» С. МаршакаIn Проблемы взаимодействия языка, литературы и фольклора и современная культура: Материалы Всероссийской научно-практической конференции, посвященной 100-летию Льва Григорьевича Барага, Mar 2011
2010
-
-
- Прототипические представления студентов о литературеIn Зарубежная литература в вузе: инновации, методика, проблемы преподавания и изучения: Сборник статей., Mar 2010
- Что такое филология?Вестник Башкирского государственного педагогического университета им. М. Акмуллы., Mar 2010
-
- РецензияРец. на кн.: Система языка: синхрония и диахрония: межвузовский сборник научных статей. — Уфа: РИЦ БашГУ, 2009. — 306 с.Mar 2010
- Тезисы докладовПроблемы автоматической морфологии агглютинативных языков и парсер башкирского языкаIn Информационные технологии и письменное наследие: материалы международной научной конференции (Уфа, 28–31 октября 2010 г.), Mar 2010
- Тезисы докладовПроект двуязычного корпуса текстов В. В. НабоковаIn Информационные технологии и письменное наследие: материалы международной научной конференции (Уфа, 28–31 октября 2010 г.), Mar 2010
- Тезисы докладовО статусе слова «поэтизм» в системе лингвистической терминологииIn Актуальные проблемы германистики, романистики и русистики. Материалы ежегодной международной научной конференции, Екатеринбург, 5–6 февраля 2010 г., Mar 2010
- Тезисы докладовОтрефлектированность ценностного статуса художественной литературы у студентов филологических факультетовIn Категория ценности и культура (аксиология, литература, язык): Материалы Всероссийской научной конференции: 13-15 мая 2010г., Mar 2010
2009
- Жанр "Поэтического искусства" Буало как системное и внесистемное явлениеIn Историческая поэтика жанра: сборник научных трудов, Mar 2009
- Analiza jedne pjesme: rezultati metodološkog eksperimentaВестник Волгоградского государственного университета. Серия 2: Языкознание, Mar 2009
- СПИКонцепт «faucon» в переводе «Слова о полку Игореве» Филиппа СупоIn Концептуальный словарь автора: Коллективная монография, Mar 2009
- «Всё громко тикает. Под спичечные марши…» С. Гандлевского как стихотворение-сценарийIn Третье литературоведение. Материалы филолого-методологического семинара (2007–2008), Mar 2009
- Тезисы докладовПроблема выравнивания при создании Параллельного корпуса переводов «Слова о полку Игореве»In Историко-культурное наследие и информационно-коммуникационные технологии: сохранение и исследование: материалы научной конференции (Пермь, 13-14 ноября 2009 г.), Mar 2009
2008
-
- СПИРасширение методов корпусной лингвистики: параллельный корпус переводов «Слова о полку Игореве»In Язык, литература и культура на рубеже XX-XXI: Сборник статей., Mar 2008
- Тезисы докладовТипология филологических «антиответов»: фоновые знания и речевые регистрыIn Культура без(с)словесности: филологиское образование в современном российском контексте. Материалы Всероссийской научной конференции, г. Воронеж, 9 октября 2008 г., Mar 2008
- Тезисы докладовОппозиция «дача—сад» в системе региональной лексики (на материале языка Уфы)In Регионально ориентированные исследования филологического пространства. Материалы Всероссийской научно-практической конференции (Оренбург, 14 ноября 2008 г.)., Mar 2008
- Тезисы докладовОпыт Параллельного корпуса переводов Слова о полку Игореве в представлении древнего текста и его переводовIn Современные информационные технологии и письменное наследие: от древних текстов к электронным библиотекам: материалы Междунар. науч. конф. (Казань, 26-30 августа 2008 г.), Mar 2008
- Тезисы докладовФранцузские стихотворения Ф. И. Тютчева в свете авторской лексикографииIn Проблемы авторской и общей лексикографии: Материалы международной научной конференции, Mar 2008
2007
- Тезисы докладовФилологический электронный инструмент: параллельный корпус переводов «Слова о полку Игореве»In Русское слово в Башкортостане. Материалы региональной научно-теоретической конференции., Mar 2007
- Тезисы докладовКорпусная лингвистика и параллельный корпус переводов «Слова о полку Игореве»In Русский язык в поликультурной среде: лингводидактические и социокультурные проблемы высшего образования. Материалы Международной научно-практической конференции, посвященной Году русского языка и 450-летию добровольного присоединения Башкортостана к России 22–23 марта 2007 г., Mar 2007
2006
- РецензияРец. на кн.: Бобунова М. А., Хроленко А. Т. Тютчев и Фет: опыт контрастивного словаря. — Курск: Изд-во Курск. гос. ун-та, 2005. — 198 с.Mar 2006
- Тезисы докладовСоотношение образных рядов в русских и французских стихотворениях Ф. И. ТютчеваIn Информатизация учебного процесса и ее влияние на повышение качества образования. Материалы российской научно-практической конференции (февраль—апрель 2006 г.), Mar 2006
- Тезисы докладовИдеографический словарь как метод исследования небольшого корпуса текстов (на материале французских стихотворений Ф. И. Тютчева)In Лингвистика текста: методы исследования: Материалы Межвузовской научно-практической конференции, Москва, 19 декабря 2004 г., Mar 2006
- Тезисы докладовИдеографическое описание языка французских стихотворений Ф. И. ТютчеваIn Народное слово в науке. Материалы Всероссийской научной конференции, г. Уфа, 12–13 апреля 2006 года., Mar 2006
- Тезисы докладовЭсхатологический миф в стихотворении Ф. И. Тютчева «Последний катаклизм»In Актуальные проблемы филологии. Материалы республиканской конференции молодых ученых, Mar 2006
2005
- Идеографический словарь как метод моделирования языковой картины мира автора (на материале французских стихотворений Ф. И. Тютчева)In Проблемы концептуализации действительности и моделирования языковой картины мира., Mar 2005
-
- Тезисы докладовЕдинство и разрушение в стихотворении Ф. И. Тютчева «Последний катаклизм»In Образование и национальная безопасность России: проблемы, взаимосвязи, перспективы: Материалы российской научно-практической конференции (февраль-апрель 2005 г.) Ч. 1, Mar 2005
- Тезисы докладовОпыт применения технологии хранилищ данных и OLAP в авторской лексикографии (на примере словаря языка Ф.И. Тютчева)In Современные информационные технологии и филология, Mar 2005
2004
-
- ПереводТютчевские переводы из Микеланджело. (Лингвистическое моделирование при анализе художественных переводов)In Традиции в контексте русской культуры. Выпуск XI: Межвузовский сборник научных работ., 2004

2003
- Образ славы в стихотворении «Цицерон» в свете античной параллелиIn Литературоведческий сборник, 2003
- ПереводПрименение лингвистической модели «смысл-текст» при анализе художественных переводов (на материале тютчевских переводов из Микеланджело)In Проблемы филологии: Сборник научных работ аспирантов, соискателей и молодых ученых, 2003
- Об одном случае актуализации внутренней формы у Ф. И. ТютчеваIn Слово в истории и функционировании: Межвузовский научный сборник., 2003
- Тезисы докладовПроект идеографического словаря языка французских стихотворений Ф. И. ТютчеваIn Языки Евразии: этнокультурологический контекст: Материалы всероссийской научно-практической конференции. 19–20 ноября 2003 г., 2003
- Тезисы докладовТютчев и барочные традицииIn Поэтическое наследие Ф. И. Тютчева: Литературоведение, лингвистика, методика: Материалы юбилейной международной научно-практической конференции, 2003
- Тезисы докладовТрадиции барокко в лирике ТютчеваIn Научный прорыв-2002. Сборник научных трудов конференции молодых ученых РБ, посвященной Году Здоровья, 70-летию БГМУ и Дню Республики, 2003
2002
- Тезисы докладовПрограмма расчета фонетического значения словаIn Проблемы современного энергомашиностроения. Всероссийская молодежная научно-техническая конференция. 26 — 27 ноября 2002 года. Тезисы докладов., 2002